Overview
Can models predict a rotated outcome before seeing it?
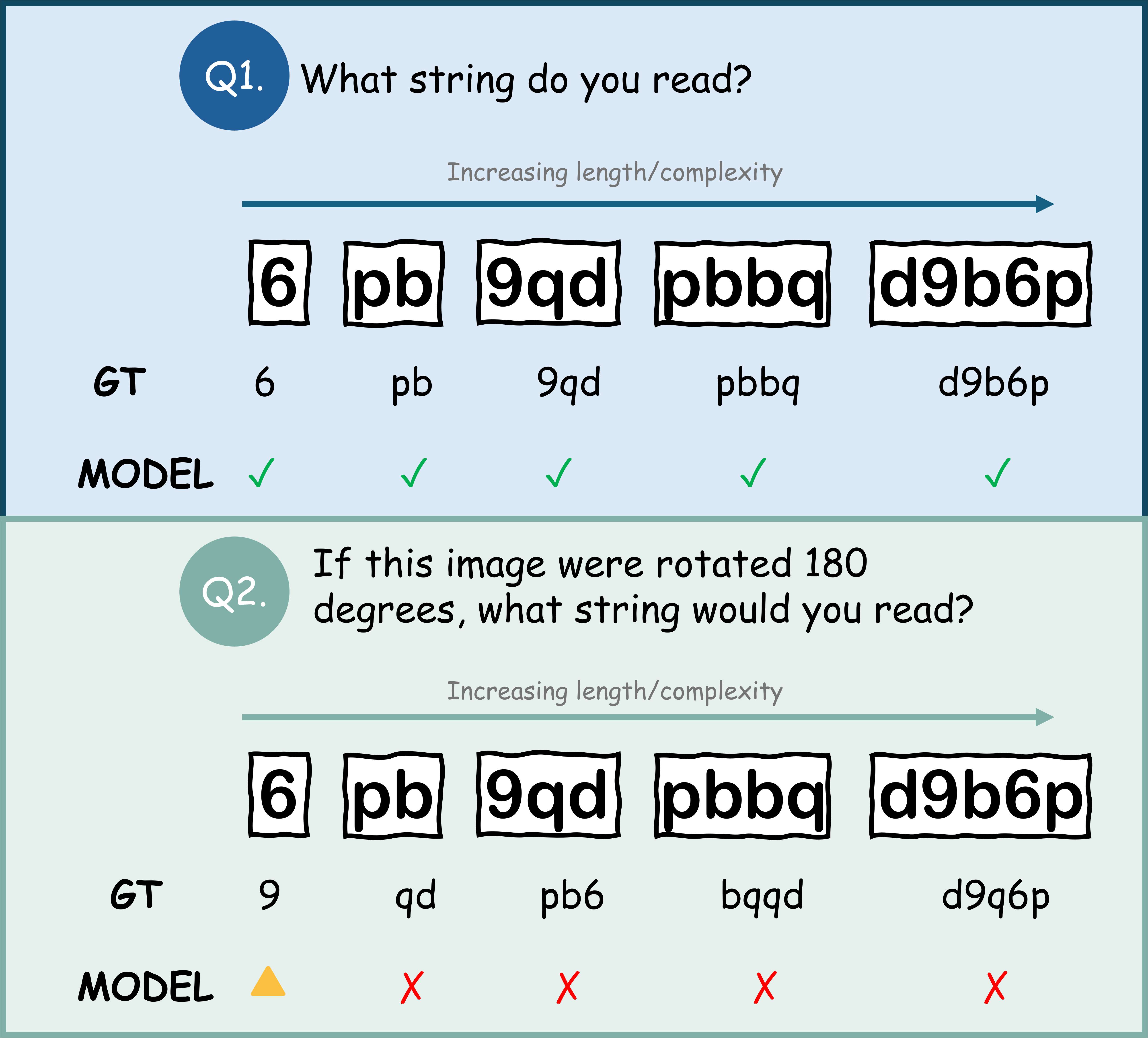
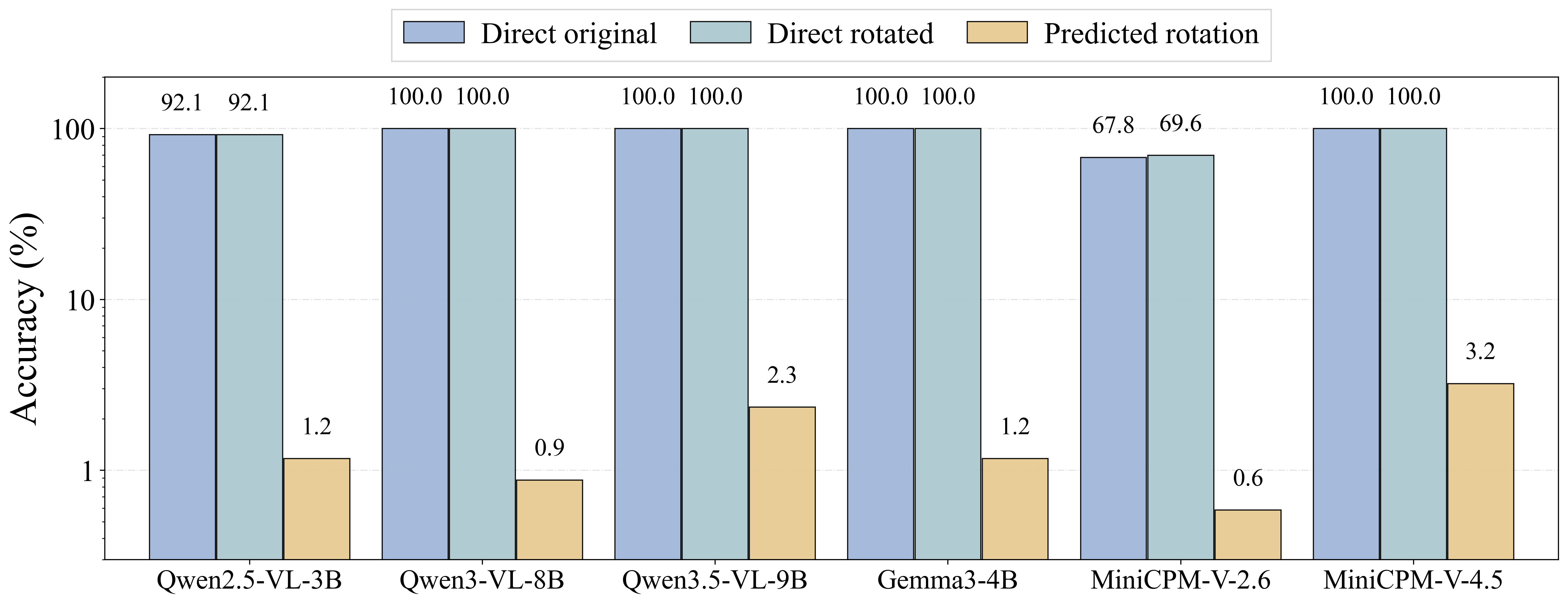
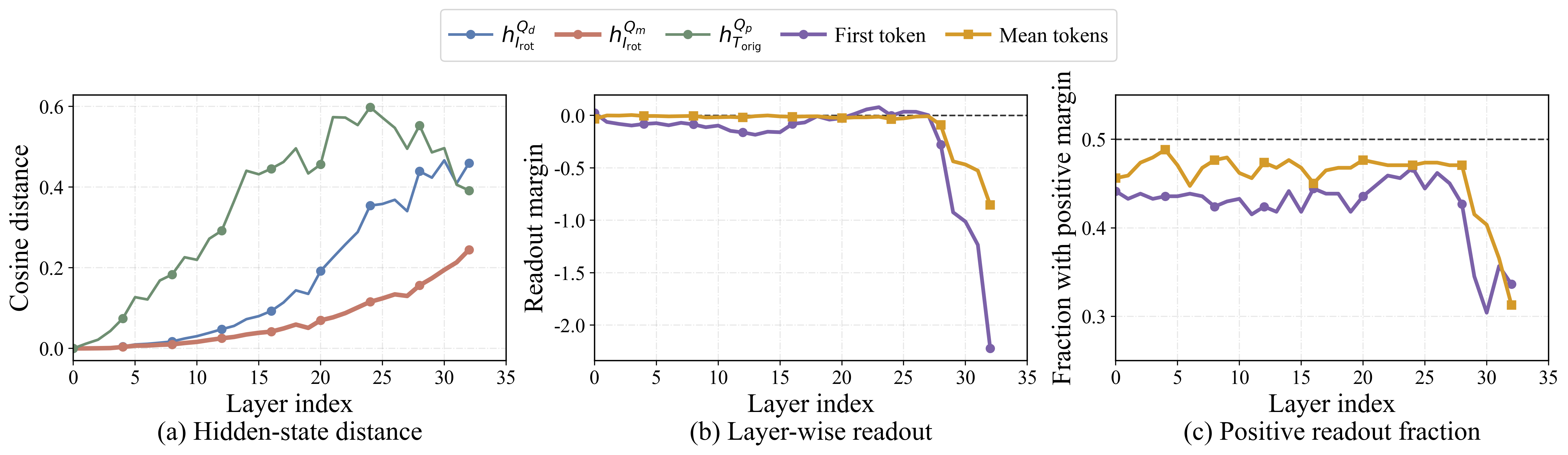
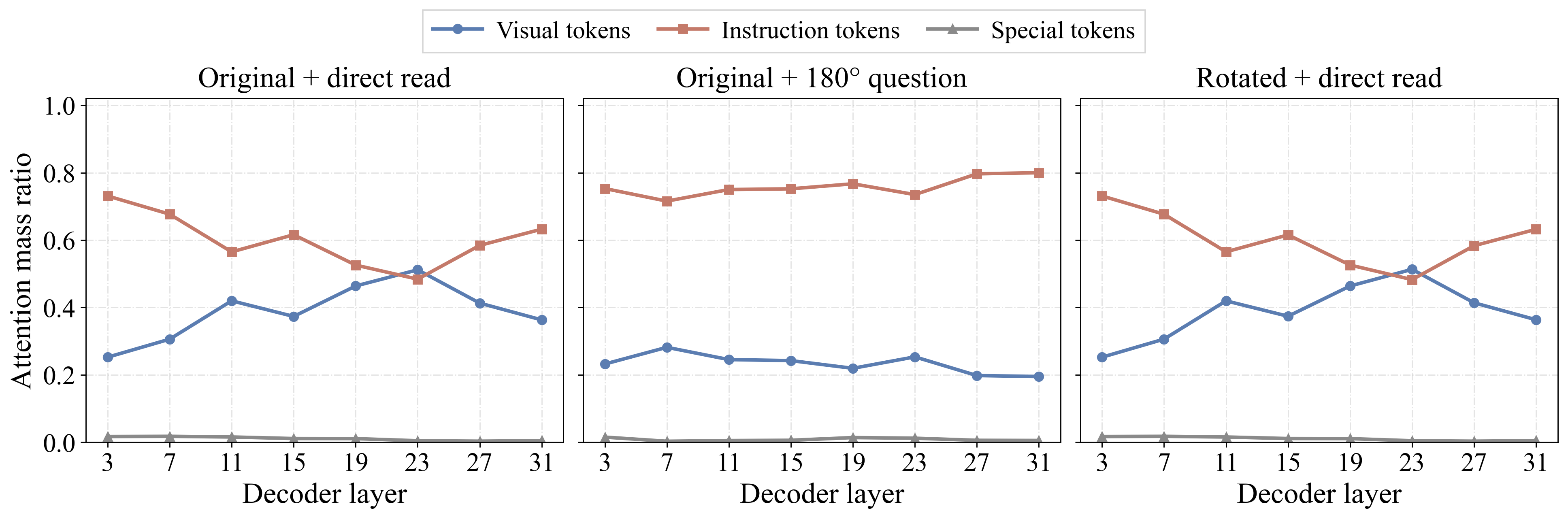
Can vision-language models predict what a 180° rotation would reveal from the original image alone? We study this ability through Rotated-Outcome Prediction: given an original image, a model must answer what would be seen or read after a 180° in-plane rotation, without directly observing the rotated target. To isolate this gap, we introduce RotOutBench, a paired diagnostic benchmark spanning open visual cases and controlled text-image rotations. A sharp pattern emerges: many VLMs can recognize the relevant content when directly given either the original or rotated image, yet fail to infer the rotated result from the original image alone. On controlled text-image rotations, predicted-rotation accuracy collapses to near zero even for models with high direct-reading accuracy.
Tasks
Two ways to test rotated-outcome prediction
Figures
Paper figures